


Data Engineering Project Quickstart Guide — Part 2

Data Engineering Project Quickstart Guide — Part 2
Understand your platforms and pipelines and know the right tools

In the first part of my quickstart guide you learned everything about the data platform blueprint and its five main parts.
In the second part we will dig a bit deeper. I will explain to you the typical pipelines of a data platform and along with it the concept of OLTP (online transactional processing) and OLAP (online analytical processing). This way you will get a better understanding of the different use cases.
Also, I’ll give you an overview of which tools are needed in which part of the platform as well as an overview of some great hands-on example projects, which you can all find in my academy as well.
Typical pipelines of data platforms
Now that you saw the different parts of a data platform you most likely want to start building. Before you do that you need to understand the difference between Online Transaction Processing (OLTP) and Online Analytical Processing (OLAP).
These are two different processes that many people mix up. They actually represent two different parts of a data platform: OLTP part for business processes & OLAP for analytics use cases.
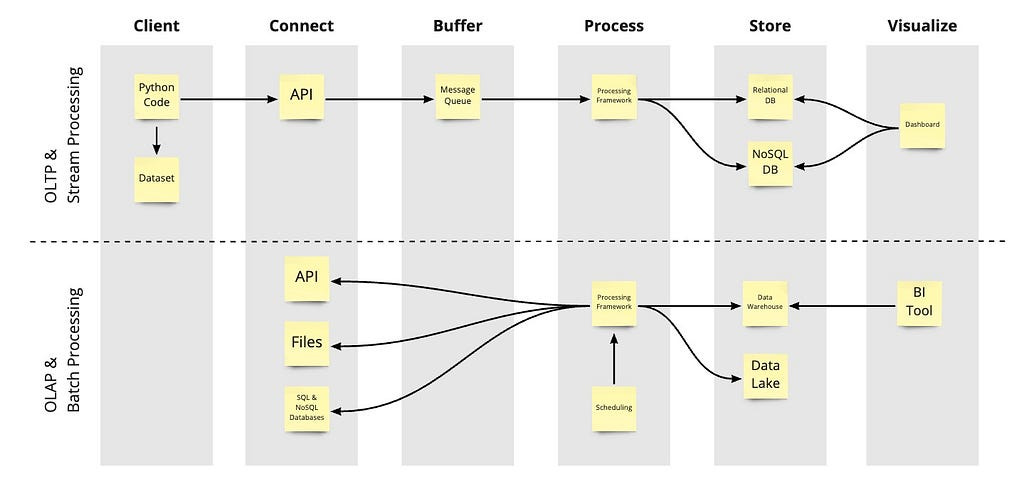
Transactional pipelines — the transactional part of a platform
The OLTP part of a data platform is often used for realizing business processes (see upper part in the image above). That’s why OLTP is more event driven and often uses streaming pipelines to process the incoming transactions (data) very quickly.
OLTP databases are ACID and CRUD compliant. They are the choice for efficiently storing transactions like store purchases.
You open a transaction, insert or modify your data and if everything is correct the transaction is confirmed and it’s completed. If the transaction fails, the store rolls back your transaction and nothing has happened. User interfaces use them very often to, for instance, visualizing your purchase history.
Another example is a factory where you produce goods. The production line queries from the database the details of what to produce next. After an item has been produced, the transactional database records that this item has been produced and some information about the production process.
Analytical pipelines — the analytics part of a platform
The analytics part of the platform is usually the part where data is coming in in larger chunks. Like once a day or once an hour. ELT jobs that run on a schedule are very often used to get the data into an OLAP store.
The data in OLAP is often less structured than in OLTP, which means you are more flexible. In OLAP stores, the data is usually simply copied in via copy commands and not via transactions.
Analysts have all the data at their disposal and are able to look at it from a completely different perspective — from a holistic perspective. They gain insights into larger amounts of data.
OLAP stores help analysts to answer questions like: Identify the customers with the highest value purchases in a month or a year. Another question could be to find the best-selling products in the shop’s inventory by month or quarter.
Tools guide
With this tools guide you can already start building your platform and pipelines. Here, you can see which tools are needed in which part of the platform blueprint and for which kind of platform they come to use.
With this, you also have a great overview of helpful tool combinations, such as Lambda, Glue and ECS for the processing frameworks on AWS, as well as great tool alternatives when working on other cloud native platforms or even cloud agnostic ones.
You can find concrete examples further below under example platforms and pipelines.

Example platforms and pipelines
Now that you have learned everything about the most important parts of building a platform, the pipelines, OLTP and OLAP, as well as all the tools you can work with, you can start with your very own data engineering project.
Here is an overview of some example platform and pipeline use cases which we see all the time in the real world and which I teach to my students via hands-on project courses:
Transactional pipelines
Data Engineering on AWS
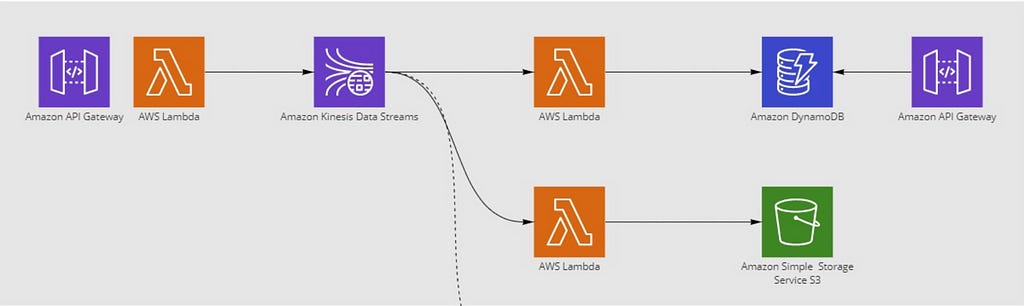
The AWS project is perfect for everyone who wants to start with Cloud platforms. Currently, AWS is the most used platform for data processing. It is really great to use, especially for those people who are new in their Data Engineering job or looking for one.
Working through AWS, you learn how to set up a complete end-to-end project with a streaming and analytics pipeline. Based on the project, you learn how to model data and which AWS tools are important, such as Lambda, API Gateway, Glue, Redshift Kinesis and DynamoDB.

You want to start on your own? Here is the link to the academy project: https://learndataengineering.com/p/data-engineering-on-aws
Document Streaming with Kafka, Spark and MongoDB

This full end-to-end example project uses e-commerce data that contains invoices for customers and items on these invoices.
Here, your goal is to ingest the invoices one by one, as they are created, and visualize them in a user interface. The technologies you will use are FastAPI, Apache Kafka, Apache Spark, MongoDB and Streamlit — tools you can learn in the academy individually, which I recommend before getting into this project.

Among other things, you learn about each step of how to build your pipeline and which tools to use at which point and get to know how to work with Apache Spark structured streaming in connection with MongoDB.
Also, you set up your own data visualization and create an interactive user interface with Streamlit to select and view invoices for customers and the items on these invoices.
Sounds like the right project for you? Here you can find it in my academy: https://learndataengineering.com/p/document-streaming
Analytical pipelines
AWS ETL Pipeline to Redshift

This project is an ETL pipeline where you take files out of S3 and put the contents into Redshift. For visualization you can use PowerBI. (This is part of the Data Engineering on AWS project)
As you are not using an API here, the data is stored as a file within S3 as clients usually send in their data as files. This is very typical for an ETL job, where the data is extracted from S3 and then transformed and stored.

A typical tool to use here is AWS Glue. With this tool, you can write Apache Spark jobs, which pull the data from S3 and then transform and store them into the destination, for which we recommend Redshift. Beside the Glue jobs, another part you should make use of is the data catalog. It catalogs the csv files within S3 as well as the data in Redshift. Thus, it becomes very easy to automatically configure and generate a Spark job in AWS Glue, which sends the data to Redshift.
As said before, the recommended storage for the analytical part is Redshift, from which the data analysts can evaluate and visualize the data. Best to use here is a single staging table in which the data is stored. The typical method here would be to use Redshift as your analytics database, to which you ideally connect a BI tool such as Power BI, for example.
Modern Data Warehouses
Google Cloud


On GCP you can start by configuring Cloud Storage, BigQuery and Data Studio on the Google Cloud Platform (GCP). We’ll put a file into the lake, create a BigQuery table and a Quicksight report that you can share with anyone you want.
AWS


Or go into AWS to set up a manual data lake integration through S3, Athena and Quicksight. After that you can change the integration to using the Glue Data catalog.
As a BONUS LESSON I share in my course how you can do what you did with AWS Athena through Redshift Spectrum.
Here you can find the complete course in my Data Engineering Academy: https://learndataengineering.com/p/modern-data-warehouses
Hadoop Data Warehousing with Hive
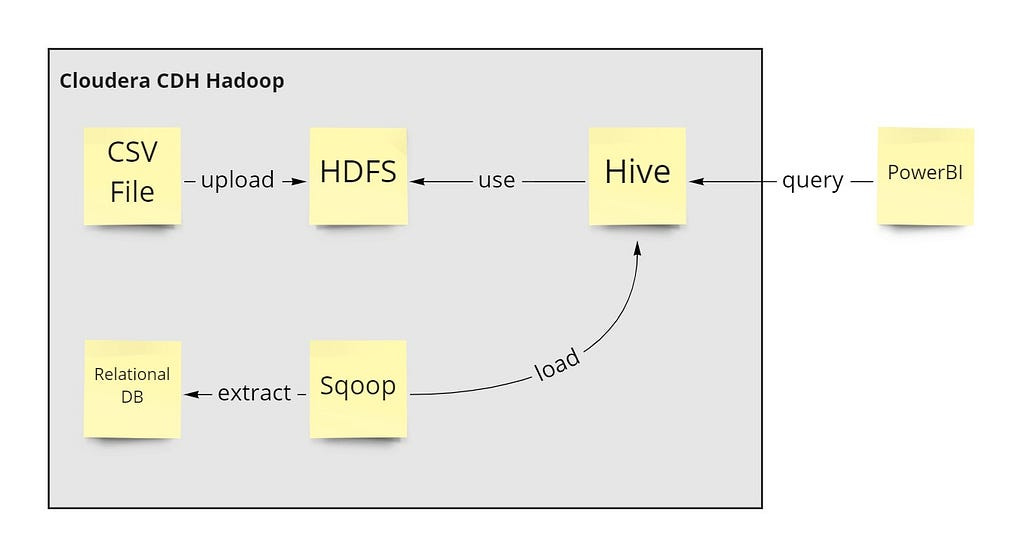
Hadoop is a Java-based and open source framework that handles all sorts of storage and processing for Big Data across clusters of computers using simple programming models.
Working through this project you will learn and master the Hadoop architecture and its components like HDFS, YARN, MapReduce, Hive and Sqoop.
Understand the detailed concepts of the Hadoop Eco-system along with hands-on labs as well as the most important Hadoop commands. Also, learn how to implement and use each component to solve real business problems!
Learn how to store and query your data with Sqoop, Hive, and MySQL, write Hive queries and Hadoop commands, manage Big Data on a cluster with HDFS and MapReduce and manage your cluster with YARN and Hue.

If you think that’s the perfect project for you, get right into it: https://learndataengineering.com/p/data-engineering-with-hadoop
Now you have everything you need to get into your first data engineering project. Have fun with the example projects and grow your skills!
More free Data Engineering content:
Are you looking for more information and content on Data Engineering? Then check out my other blog posts, videos and more on Medium, YouTube and LinkedIn!
Data Engineering Project Quickstart Guide — Part 2 was originally published in Plumbers Of Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.