
Data Engineering Roadmap for Data Analysts
The step by step guide for your success

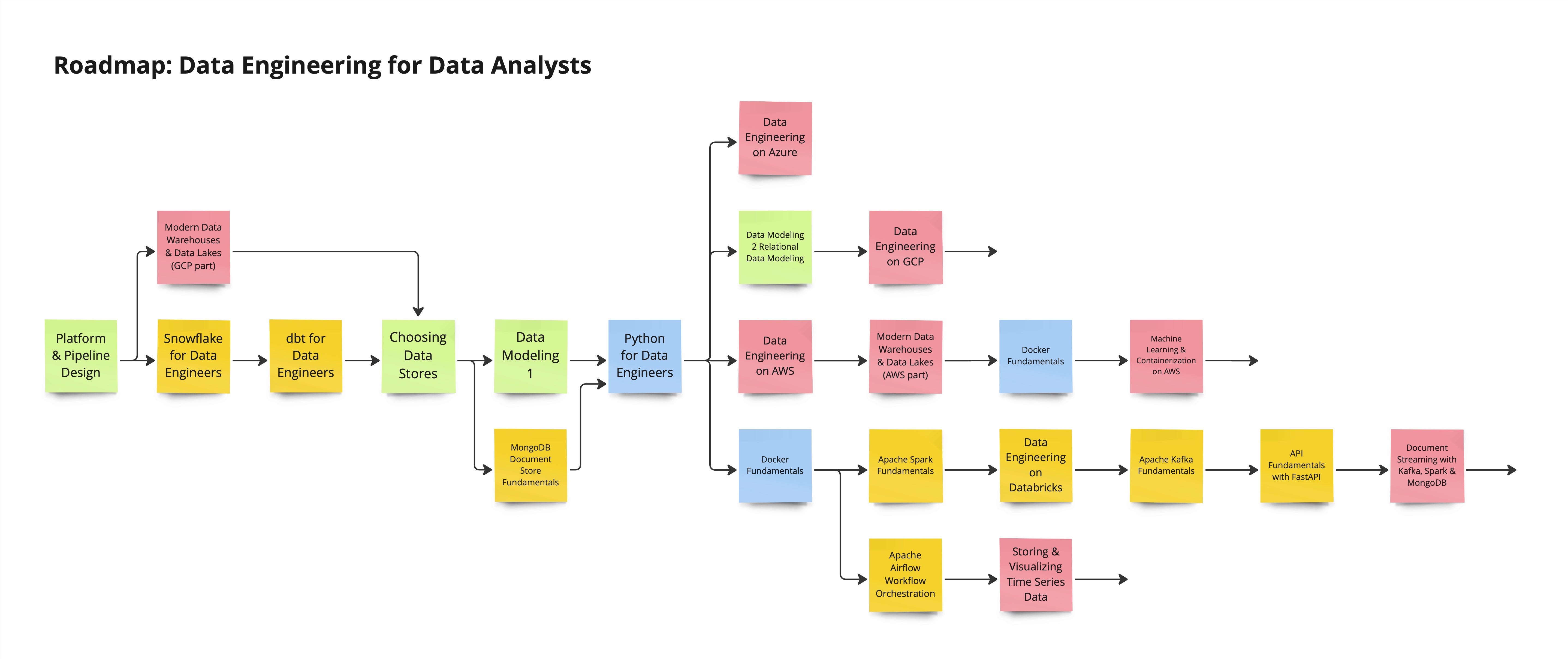
I always advise my students to begin with familiar concepts and knowledge, then expand from there. As a data analyst working with data warehousing and report preparation, one might wonder where to start. Rather than diving into basics, it's beneficial to begin with understanding platform and pipeline fundamentals. This includes grasping the architecture of platforms and proceeding to more advanced topics.
Read more in my free 80+ pages Data Engineering Cookbook: Click Here
For instance, if you're familiar with data warehousing, you might explore BigQuery for warehousing or delve into the lakehouse concept on Snowflake or Google Cloud Platform (GCP). The ease of setup with these platforms allows for immediate application of existing knowledge through data uploading and manipulation. Additionally, our course offerings, such as one on Snowflake with DBT, enable further exploration into data transformation within these environments.
Understand different data stores
The next step involves selecting appropriate data stores, understanding the differences between OLTP (Online Transaction Processing) databases and analytical data stores, including NoSQL and traditional relational databases. This understanding is crucial for effective data modeling, which we cover in our courses, offering insights into various database modeling techniques.
Moreover, for those interested in non-relational databases, MongoDB presents a valuable opportunity to skip relational data modeling in favor of document stores, leveraging prior knowledge in warehousing and dimensional modeling.
Python
Python skills, even at a basic level, are essential for data engineers. Our Python for Data Engineers course aims to enhance understanding of data transformation tools and techniques. This knowledge, combined with insights into data warehousing, platform functionality, data modeling, and store selection, equips you with the skills to utilize Python in data engineering effectively.
Leverage The Cloud Platforms
For analysts ready to explore further, projects focusing on fundamental tools and platforms become the next step. Whether it's building streaming data pipelines in Azure that integrate with NoSQL databases like Cosmos DB, or diving into relational data modeling on GCP, there's a wealth of paths to explore. Our courses also cover modern data warehouses and lakehouses on both AWS and GCP, providing comprehensive knowledge on data integration and management.
Use Containerization with Docker
Additionally, understanding Docker fundamentals opens up possibilities for containerization and machine learning projects, further enhancing your toolkit. From there, diving into Spark fundamentals, learning Kafka for data streaming, and mastering APIs can lead to developing end-to-end streaming projects with user interfaces.
In summary, the journey from understanding basic platform and pipeline concepts to mastering advanced data engineering tools and techniques is a gradual process. By focusing on familiar areas and progressively expanding your skill set, you can achieve a solid foundation in data engineering. This approach, especially if documented well, can set you apart in the field, even at an entry-level or junior position.
Watch the Live Stream recording on YouTube
In this live stream I was showing step by step how to read this roadmap for Analysts, why I chose these tools and why I think this is the right way to do it. I also answered many questions from the audience.
🍀
Read my free 80+ pages Data Engineering Cookbook on GitHub: Read the Cookbook
Follow me on: LinkedIn | Instagram | X (Twitter) | YouTube |
Learn Data Engineering at my Data Engineering Academy, trusted by over 1,500 students 💪: Click here to learn more