
Data Engineering Roadmap for Data Scientists
The step by step guide for your success

In this post we’re going to tackle the data engineering roadmap for data scientists. It's a topic a lot of you have been curious about, especially after we explored the data analyst side of things. The goal here is to lay out a step-by-step path for those of you looking to make a pivot or deepen your understanding of data engineering.
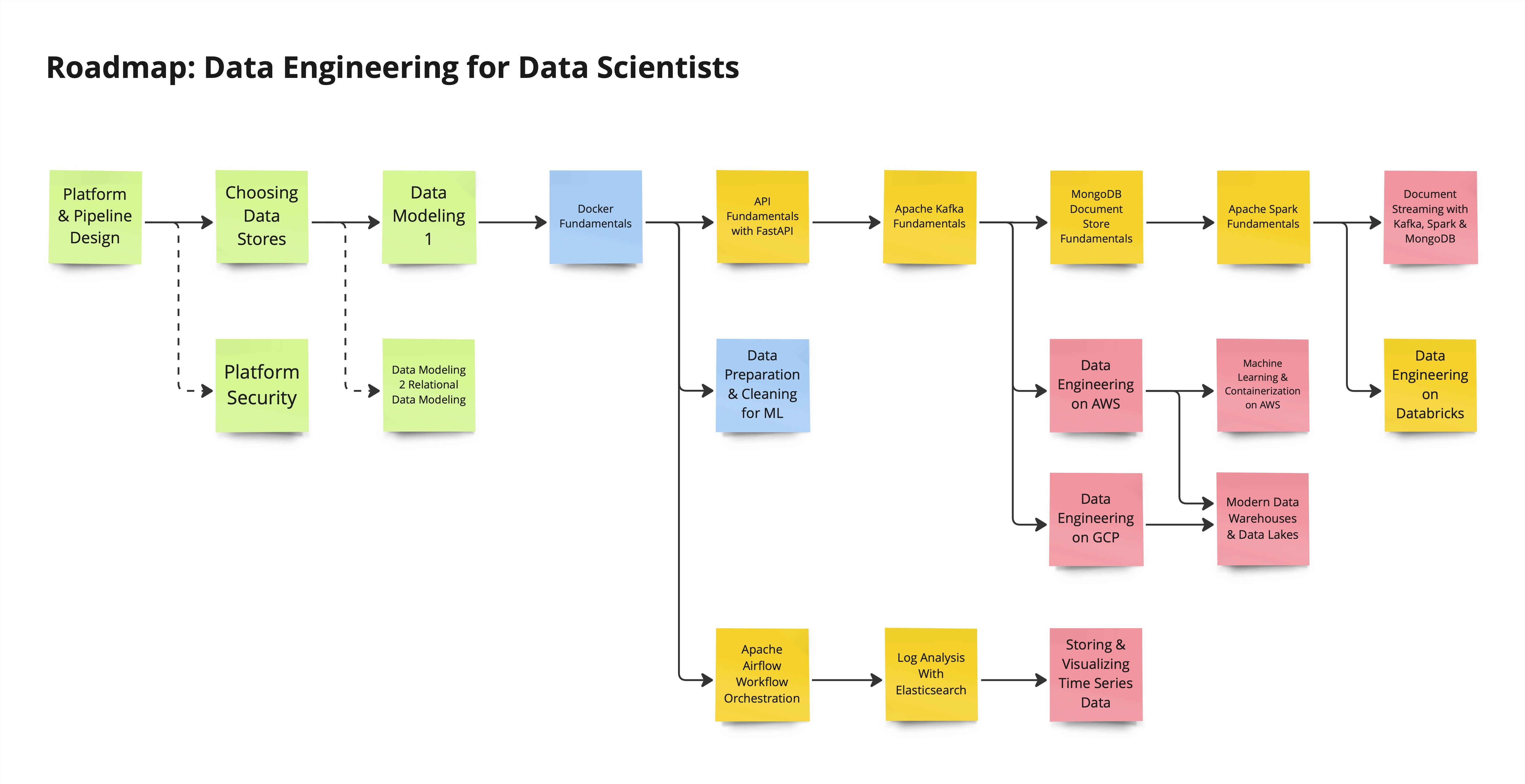
The first thing I did was sit down and list out all the courses available in my academy. It’s designed to be super flexible, catering to different job roles. For a data scientist, your journey usually starts with a strong grasp of data science fundamentals, right? You know your way around machine learning, how to preprocess data, and maybe even deploy models on a basic level. But then, the question arises: How do you set up an entire platform or pipeline that takes data from ingestion to a point where it’s usable for others?
The Basics
Here’s where it gets interesting. I thought about how we could structure this to really benefit data scientists. Starting with the basics, like platform and pipeline design, and then moving into choosing data storage solutions. We’re talking about understanding the differences between databases and when to use each type.
But it doesn’t stop there. I’ve included some optional topics, like platform security, because it’s always handy to know, even if you’re not directly responsible for it. And since you’re already familiar with data, why not dive deeper into data modeling? It’s all about making your data work for you in the most efficient way possible.
Docker & The Cloud
Now, let's talk about Docker. It's a game-changer for deploying your algorithms. And after that, mastering API fundamentals and streaming with Apache Kafka will open up new possibilities for your projects.
Depending on your interests or where you see yourself in the future, you might want to explore cloud services like AWS, GCP, or Azure. Or maybe you’re more intrigued by the idea of document streaming and creating user interfaces with MongoDB and Streamlit. The roadmap I’ve laid out includes paths for all these directions.
Observability
Monitoring and observability are crucial, too. You’ll want to keep an eye on your algorithms and the data flowing through your systems. Tools like Elasticsearch or InfluxDB paired with Grafana can give you those insights.
And don’t forget about orchestration with Airflow. It’s all about keeping your workflows organized and efficient.
So, this roadmap is more than just a list of topics. It’s about building a foundation that lets you, as a data scientist, expand into data engineering seamlessly. It’s about understanding the ecosystem around your data and how to leverage it to build robust, scalable solutions.
Watch the Live Stream recording on YouTube

In this live stream I was showing step by step how to read this roadmap for Scientists, why I chose these tools and why I think this is the right way to do it. I also answered many questions from the audience.
🍀
Read my free 80+ pages Data Engineering Cookbook on GitHub: Read the Cookbook
Follow me on: LinkedIn | Instagram | X (Twitter) | YouTube |
Learn Data Engineering at my Data Engineering Academy, trusted by over 1,500 students 💪: Click here to learn more